Real Goal - Get you talking about your data challenges
Single ’omics Challenges
What did all those ’omics datasets have in common?
What is your research question?
Define your biological question clearly before choosing methods
- Discovery: Find patterns, generate hypotheses
- Prediction: Build models to predict outcomes
- Inference: Test specific biological hypotheses
What are you really measuring?
Understanding your data type matters for analysis choices
- Counts: RNA-seq, 16S - discrete, compositional
- Intensities: Proteomics, metabolomics - continuous, batch effects
- Binary/Categorical: Presence/absence, SNPs
- Each has different assumptions and appropriate methods
Are my data compositional?
Compositional data requires special care
- What is it: Parts of a whole (relative abundance, %)
- The problem: Sum to 1 constraint creates spurious correlations
- Examples: Microbiome, some metabolomics, cell type proportions
- Solutions: CLR transformation, ALR, isometric log-ratio
- Real Solutions Spike-ins, integrating absolute quantification methods
Are my data sparse?
Sparsity (many zeros) affects method choice
- Technical zeros: Below detection limit - consider imputation
- Biological zeros: Truly absent
- Common in: Microbiome, single-cell RNA-seq, proteomics
- Approaches: Zero-inflated models, filtering, imputation
- Trade-off: Filter too much vs. keep noise
Case study: Preterm birth
We know the vaginal microbiome is associated with preterm birth
We know preterm birth is often accompanied by inappropriate inflammation
Let’s measure inflammation and the microbiome at the same time, and figure out what our question is later!
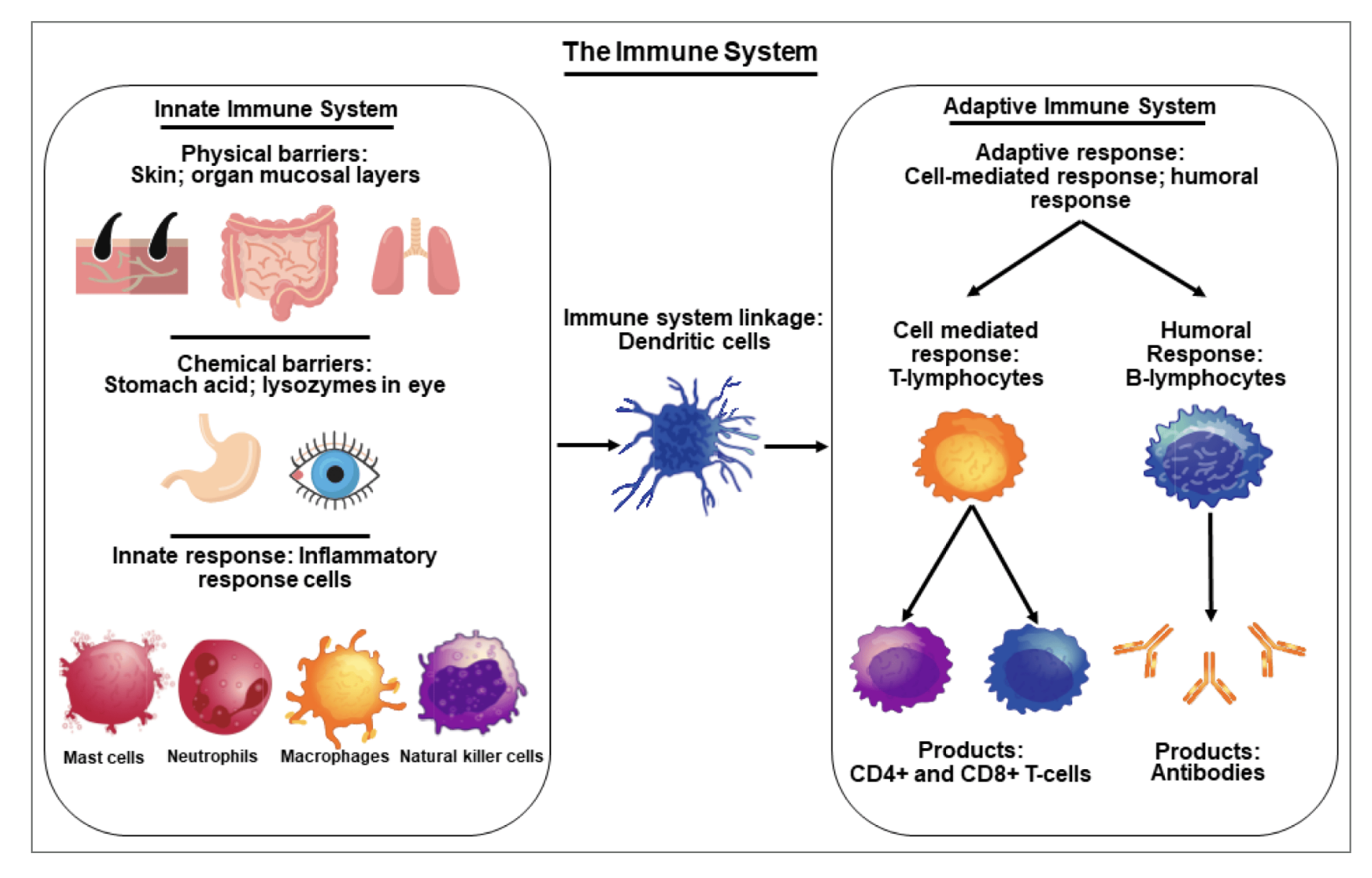
Measuring inflammation
“Inflammation” isn’t one thing - it is an incredibly complex and varied process with cells changing phenotype, proliferating and dying, and signaling each other.
![]()
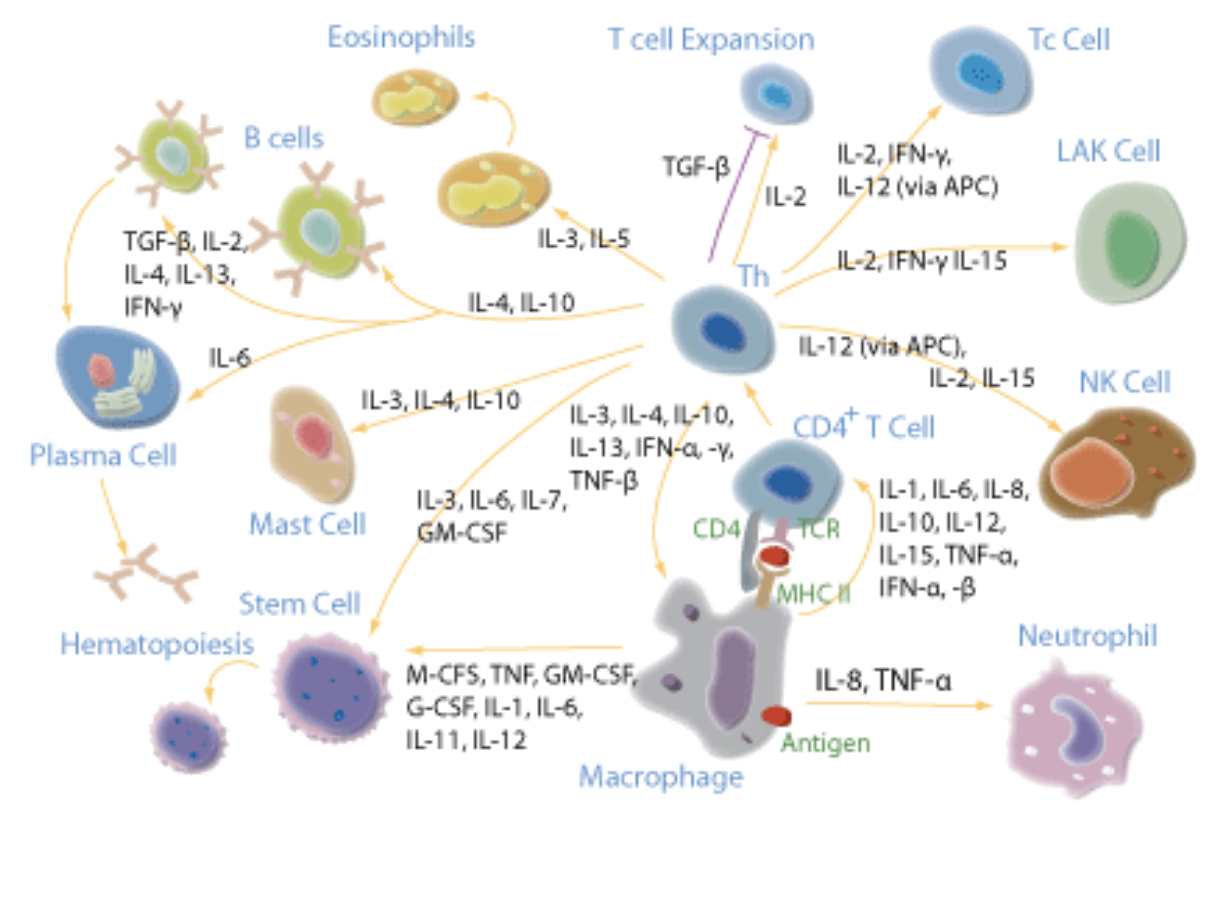
Measuring cytokines
In our case, we’re measuring cytokines which are small secreted peptides that signal immune cells and epithelial cells.
Cytokines are often expressed together and might be redundant. What do we expect when we measure them?
![]()
Excalidraw to talk about cytokine measurement
Measuring microbiota
What are 3 ways we can measure complex microbial communities?
![]()
Excalidraw talking about 16S
Live coding of 16S analysis